Headline Sentiment Reactions
Exploring how news headlines drive sentiment and engagement on social media
Collaborators:
Tony Lin | Ahmeda Cheick

In a Nutshell
This project showcases the power of NLP, machine learning, and data visualization to analyze the interplay between editorial strategies and audience sentiment.
It provides a framework for responsible headline crafting and paves the way for more balanced, engaging digital news content.
Overview
Investigates how Facebook “Reactions” reflect audience sentiment towards news headlines.
Focuses on headlines from 16 major U.S. news outlets, analyzing editorial framing and emotional engagement.
Objectives
Explore how headlines from prominent U.S. news organizations influence audience reactions on Facebook.
By leveraging Facebook’s “Reactions” feature, we aimed to quantify and analyze the sentiment and emotional impact of news headlines.
This research provides insights into how editorial framing shapes audience sentiment and emotional engagement, highlighting variations in tone across different news outlets.
Methodology
Sentiment Scoring
Developed a scoring system for Facebook Reactions for the first time.
Classified headlines into binary (positive/negative) and multiclass labels.
Modeling:
Tested various machine learning models, including:
Baseline: Pre-trained BERT.
Advanced: Hybrid BERT-CNN models to combine contextual understanding and local text features.
Comparative: RNNs and attention-based models.
Key Results
Sentiment Trends:
Most headlines skewed neutral to negative, with “Sad” and “Angry” reactions dominating.
Significant differences in sentiment across outlets for the same events, revealing editorial framing.
Model Performance:
Hybrid BERT-CNN achieved highest accuracy:
71% for binary classification.
55% for multiclass classification.
Highlighted the complexity of modeling nuanced reactions like “Haha” and “Care.”
This project is part of the curriculum for “Course 266 — Natural Language Processing” at the UC Berkeley School of Information.
If you enjoyed this project and would like to explore the code or learn more about my work, you can find all the details at the links below



Project Introduction
In today’s digital era, social media has surpassed print as the primary news source, reshaping how information spreads and revenue is earned. Here, headlines wield immense power—shaping perceptions, driving engagement, and often deciding an article’s fate.
Yet this influence has a hidden cost. Many readers engage only with headlines, never clicking through, inadvertently fueling misinformation. These “Shares Without Clicks” (SwoCs) can skew understanding and erode trust, all while boosting engagement metrics.
Our project tackles this challenge by modeling how headlines trigger emotional responses, using Facebook Reactions data.
We aim to guide newsrooms toward more ethical headline practices—balancing engagement with integrity.
By doing so, we hope to foster a healthier digital news environment, one that encourages critical thinking, nuanced understanding, and more meaningful public discourse.

Emojis and Facebook Reactions enhance emotional expression in digital communication, offering an engaging way to convey nuances text often misses. Despite their role in non-verbal communication, research on quantifying their emotional content remains limited.
To date, no lexicon specifically focused on Facebook Reactions has been developed, making this study the first of its kind.
Data Collection
We selected sixteen prominent news outlets and identified ten dates in 2023 for data collection, ensuring stable engagement metrics before capturing content.
We manually captured data by taking screenshots of each news post, as automated tools like Netvizz were no longer available after policy changes. This approach ensured we could still reliably gather information from multiple major news outlets.
We employed the OpenAI ChatGPT API to extract essential details, such as headlines and reaction counts, directly from these screenshots. By streamlining the data extraction process, we reduced the workload and improved accuracy.
To better understand audience sentiment, we excluded the overwhelmingly dominant “Like” reactions, allowing subtler emotions to emerge. By focusing on less frequently used reactions, we gained clearer insights into the nuanced emotional engagement behind each headline.

Facebook Reactions Sentiment Scores and Labeling Headlines
This study represents the first dedicated effort to integrate sentiment scores from Facebook Reactions into headline sentiment analysis.
We started by using NLTK VADER to calculate headlines sentiment polarity.
Next, we developed the Facebook Reactions Sentiment Score (FRSS), assigning weights to “Love,” “Care,” “Wow,” “Haha,” “Sad,” and “Angry” based on their inherent emotional tones.
Applying these weights, we derived a Headline Sentiment Score (HSS) that blends text-based polarity with audience reactions, ultimately classifying headlines into four sentiment classes.

By merging traditional sentiment analysis with nuanced engagement-driven cues, this approach illuminates patterns in how audiences emotionally respond to headlines, offering richer insights into the sentiment landscape of digital news.


Modeling
Binary Classification
BERT Baseline: We started with a baseline BERT model achieving about 67% accuracy, providing a fundamental performance threshold. Freezing the transformer layers reduced overfitting but limited domain-specific nuance capture.
DistilBERT: DistilBERT failed to correctly classify any positive headlines, exploiting class imbalance rather than understanding sentiment. Its poor performance underscores the difficulty of adapting general language representations to complex headline nuances.
CNN: A basic CNN model surpassed random guessing but struggled to generalize beyond simple patterns. Without deeper contextual cues, it often approached near-baseline results.
RNN (with/without Attention): RNNs offered only marginal improvements and frequently reverted to near-baseline performance. Even with attention, these models couldn’t robustly discriminate between sentiment classes.
Hybrid BERT-CNN: The hybrid BERT-CNN model, combining frozen BERT layers with convolutional feature extraction, achieved the highest accuracy of 71%. This architecture balanced computational efficiency and predictive performance, outperforming the baseline and other tested models.
Multiclass Classification
BERT: We extended to four sentiment categories—Positive, Slightly Positive, Negative, and Slightly Negative—using a BERT-based model as the baseline. Achieving a testing accuracy of 38.6%, BERT demonstrated resilience despite the challenges of nuanced classes and imbalanced data.
CNN: The CNN model reached 47.9% accuracy, outperforming BERT by effectively leveraging spatial patterns. However, signs of overfitting emerged, highlighting the complexity of the dataset and the need for improved regularization techniques.
RNN: With 36.2% accuracy, the RNN showed modest success but did not surpass BERT’s performance. While capturing some sequential dependencies, it struggled with the task’s intricacies and label imbalance.
These results underscore the inherent difficulty of multiclass sentiment analysis on imbalanced data. Further optimization, refined preprocessing, and potentially more advanced architectures are needed to improve performance in future efforts.
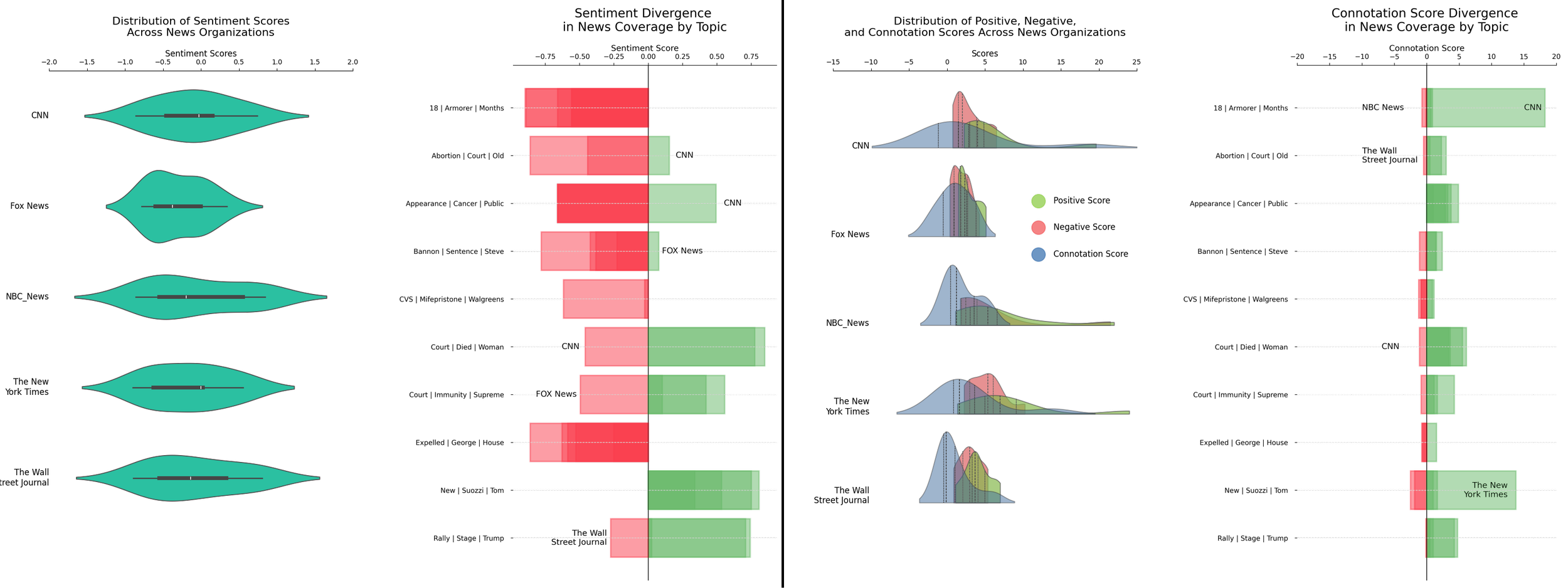
Cross-Outlet Events
In today’s competitive digital landscape, news outlets often tailor their headlines to resonate with their audience’s preferences and capture reader engagement. Different media organizations may frame the same story in distinct ways—emphasizing certain emotions, angles, or keyword choices—in order to attract visibility and prompt interaction, all while adapting to the tastes of their followers.
This variation in headline sentiment not only influences how an event is perceived, but also how widely it is shared, discussed, and trusted across different platforms.
To further examine how sentiment might vary when multiple outlets cover the same event, we assembled a smaller dataset of fifty news articles drawn from five distinct news organizations. These fifty articles represented ten separate events, with each event covered once by each of the five outlets, yielding a controlled set of comparisons. By grouping the articles into segments of five, each segment focusing on a single event, we could analyze how sentiment shifted as reporting moved from one outlet to another.





NLTK VADER Sentiment Scores
Leveraging the NLTK VADER model, we systematically assigned sentiment scores to headlines covering identical events reported by multiple news outlets.
This approach enabled us to observe how different organizations, even when presenting the same underlying facts, could employ wording choices that significantly influenced the emotional tone.
In some cases, these distinctions manifested as subtle differences in phrasing that nudged an event’s portrayal toward a more positive, neutral, or negative sentiment.
The consistent variability in scores across outlets underscores that sentiment is not solely derived from the factual content of the event. Rather, it also emerges from the editorial decisions and stylistic conventions each source uses to frame that content.
This interplay of choices suggests that VADER-based sentiment analyses must consider not only the event itself, but also the unique linguistic character that each outlet brings to its reporting.
SentiWordNet Connotation Analysis
Expanding beyond the aggregated sentiment scores provided by VADER, incorporating SentiWordNet allowed us to delve deeper into the nuances of word-level connotations.
Through this connotative analysis, we uncovered how seemingly minor changes in vocabulary—such as selecting a more emotionally charged synonym or opting for a subtly negative term—could alter the perceived sentiment of a headline.
While the core terms referencing the event remained consistent across outlets, their surrounding lexical choices varied in meaningful ways. For instance, one outlet might use a term with a mildly positive connotation, while another, covering the same event, could choose a word bearing a negative shade of meaning.
These shifts, captured by SentiWordNet, emphasize the importance of considering word-level emotional cues. By doing so, sentiment modeling can more accurately reflect the editorial “fingerprint” left by each outlet on otherwise identical news events, recognizing that headlines are not merely factual statements but storytelling devices shaped by language and audience-oriented strategy.
Conclusions
This study introduces a novel sentiment scoring system for Facebook Reactions and applies a hybrid BERT-CNN model to analyze how headline framing affects audience sentiment. Results reveal a tendency toward neutral to negative sentiments across outlets and highlight the complexity of interpreting ambiguous reactions, particularly in multiclass scenarios.
By demonstrating the interplay between language choices, emotional cues, and reader engagement, this work provides insights that can guide more ethical and effective headline crafting. Ultimately, these findings underscore the potential of sentiment modeling to encourage more balanced and responsible discourse in the digital news landscape.